SMILES 规则
这是一篇作者古早时期写的一篇类科普文,舍不得删,就放这了。
前言
SMILES (Simplified Molecular Input Line Entry System 简化线性分子输入规范),是一种 ASCII 字符串编码,用以描述分子结构,也是计算化学中常用的语言。
Canonical SMILES : 个化合物的唯一 SMILES 字符串,由"正则化"算法生成。(a unique SMILES string of a compound, generated by a "canonicalization" algorithm.)
Isomeric SMILES : 一个具有立体化学和同位素规格的 SMILES 字符串。异构 SMILES 是指扩展的,可以表示同位素、手性和双键结构的 SMILES 版本。它的一个显著特征是可以精确地说明局部手性。(a SMILES string with stereochemical and isotopic specifications.)
SMILES 把分子结构表示为任意的手性特征图,本质上就是分子家描述分子结构的二维图片。仅仅描述分子图 (即原子和化学键,没有手性或者同位素信息) 的 SMILES 叫做一般 SMILES。对于给定的结构,通常有很多一般 SMILES 表示方法;规范化算法用于在所有有效可能性中生成一个特殊的通用 SMILES,这个特殊的 SMILES 叫做 Canonical SMILES;用同位素和手性规格书写的 SMILES 叫做 Isomeric SMILES ;唯一的 Isomeric SMILES 叫做绝对 SMILES。
规范
原子
- 原子用它们的原子符号表示:这是 SMILES 中唯一需要使用的字母,双字符符号的第二个字母必须以小写字母输入,每个非氢原子由其括在方括号
[]中的原子符号独立指定 - 对于 B,C,N,O,P,S,F,Cl,Br 和 I 等原子,如果连接的氢原子数量和原子的最低正化合价相同,则
[]可以省略 - 在
[]内,必须始终指定连接的氢原子数量和原子当前的化合价。氢的数量用符号 H 表示,后跟可选数字。类似地,化合价由符号 + 或 - 之一表示,后跟可选数字,并用于表示原子所带电荷。如果未指定,则对于[]内的原子,就假定连接的氢和电荷的数量为零 - 脂肪族碳由大写字母 C 表示,芳香族碳由小写字母 c 表示
一些简单的石栗:
| SMILES 码 | 化学式 | 中文名称 |
|---|---|---|
| C | CH4 | 甲烷 |
| P | PH3 | 膦 |
| N | NH3 | 氨 |
| S | H2S | 硫化氢 |
| Cl | HCl | 氯化氢 |
| O | H2O | 水 |
| [CH2] | :CH2 | 卡宾 |
| [CH4] | CH4 | 甲烷 |
| [C] | C | 碳原子 |
| [H+] | H+ | 质子 |
| [OH-] | OH- | 氢氧根离子 |
| [Fe++] | Fe2+ | 亚铁例子 |
| [Fe+2] | Fe2+ | 亚铁离子 |
| c1ccccc1 | C6H6 | 苯 |
化学键
单键,双键,三键和芳香键分别用符号 -,=,# 和 : 表示,均为英文符号
通常假设相邻原子以单键 / 芳香键的形式相互连接,一般总是省略单键和芳键,出现歧义时可额外带上说明
带有分支时,通过
()指定,可以堆叠,带有分支的原子写在左侧,分支上的元素写在右侧由
.分隔的相邻原子意味着原子彼此不键合,用于离子键等断开结构
一些石栗:
| SMILES 码 | 化学式 |
|---|---|
| CC | C2H6 |
| CCO | C2H5OH |
| COC | CH3OCH3 |
| [H]\[H] | H2 |
| C=O | CO |
| C=C | C2H4 |
| O=C=O | CO2 |
| C#N | HCN |
| CC(C)(C)C | C(CH3)4 |
| CCN(CC)CC | N(C2H5)3 |
| CC(=O)O | CH3COOH |
| CC=C(C(C)C)C=O | CH3CH=C(i-Pr)CHO |
| [Na+].[Br-] | NaBr |
| CC(=O)[O-].[Na+] | NaAc |
对于环状结构,通过在每个环中断开一个键来表示,这个键的选取通常是任意的,为避免歧义常选单键断裂。该键以任何顺序编号,在每个闭环时紧跟原子符号后用数字表示开环(或闭环)键。然后即可按照线性结构命名

根据短键方式和编号顺序,通常一个环状化合物会获得不同的 SMILES 码
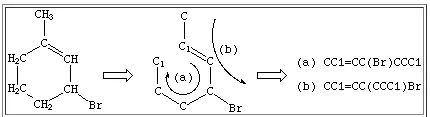
如果需要,表示环闭合的数字可以重复使用,出现几对数就表明成了几个环,为避免歧义也可依次使用数字表示开环
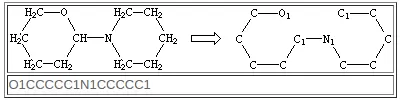
Isomeric SMILES
一些适用于 Isomeric SMILES 的特殊规则和语法
描述和作用的对象都是某一原子而非整个分子
同位素
- 在原子符号前面用一个数字表示所对应的原子质量
- 只能在
[]中指定同位素原子
| Isomeric SMILES | 中文名称 |
|---|---|
| [12C] | 碳-12 |
| [14C] | 碳-14 |
| [C] | 碳 |
| [14CH4] | 碳-13 甲烷 |
| CC(=O)[18O] | 氧-18 标记羟基氧的乙酸 |
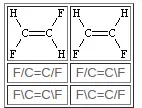
双键
双键周围的配置由 / 和 \ 指定,它们是“方向键”,可以被认为是单键或芳香键(例如默认键)的种类,即在未指定时可以进行省略。 这些符号表示连接原子之间的相对方向性,并且只有当它们出现在两个双键连接的原子上时才有意义。
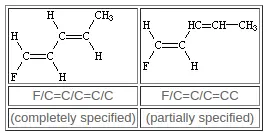
四面体与手性中心
与 R/S 规则类似,Isomeric SMILES 中用 @ 表示逆时针,用 @@ 表示顺时针,在手性原子右侧加以描述,并用 [] 来指定,不同的是,Isomeric SMILES 中可以不以最小的原子序数的原子为基准进行方向的判断,而是在描述 SMILES 时当某一原子置于手性原子前,以该原子为基准向手性原子进行方向的判断,若以 H 原子为基准时,可以将 H 与手性原子一同指定。
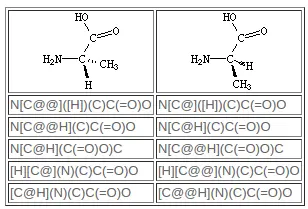
环闭合键的手性顺序由环闭合数字出现在手性原子上的词汇顺序暗示(不是“取代基”原子的词汇顺序)。
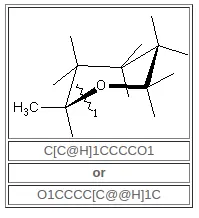
SMILES 公约
氢
在为大多数有机结构编写SMILES时,通常不需要指定氢原子。 氢的存在可以通过三种方式指定:
对于没有括号指定的原子,从正常的价假设。
在括号内,通过提供的氢计数明确计数;如果未指定,则为零。
作为 [H] 原子。
“有机”和“无机”在 SMILES 命名法之间没有区别,可以指定任何SMILES中任何原子的连接氢的数量。例如,丙烷 CCC 也可以作为[CH3] [CH2] [CH3]输入。
有四种情况需要明确氢的规范:
带电的氢,[H+]
与其他氢连接的氢,例如分子氢,[H][H]
氢连接到除另一个原子以外的氢
同位素氢,例如在重水中,[2H]O[2H]
芳香性
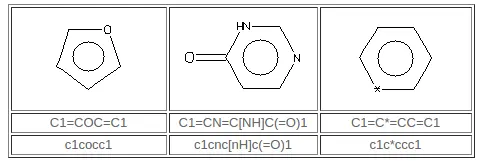
SMILES 算法使用 Hueckel 规则的扩展版本来识别芳香分子和离子。为了具有芳香性,环中的所有原子必须是 sp2 杂化的,并且可用的“过量”p电子的数量必须满足 Hueckel 的 4N + 2 标准。例如,苯写成 c1ccccc1,但 C1=CC=CC=C1 环己三烯(Kekulé形式)的条目导致芳香性的检测并导致内部结构转换为芳香族表示。相反,c1ccc1 和 c1ccccccc1 的条目将产生环丁二烯和环辛四烯的正确抗芳香结构,C1=CC=C1 和 C1=CC=CC=CC=C1。在这种情况下,SMILES 系统寻找一种结构,该结构保留隐含的 sp2 杂交,隐含的氢计数和指定的正式电荷(如果有的话)。但是,某些输入可能不仅是不正确的,而且也是不可能的,例如 c1cccc1。这里 c1cccc1 不能转化为 C1=CCC=C1,因为其中一个碳原子是 sp3,带有两个连接的氢。在这种结构中,不能进行交替的单键和双键分配。 SMILES 系统会将此标记为“不可能”的输入。请注意,以下列表中的原子只能被视为芳香族:C,N,O,P,S,As,Se和 *(通配符)。此外,环外双键不会破坏芳香性。
电荷与化合价
SMILES 没有规定应该使用哪种化合价来模拟分子结构。 事实上,使用 SMILES 的一个优点是它能够描述相同结构的各种价模型。 可以连接原子并根据需要显示电荷分离。 例如,硝基甲烷可以在 SMILES 中表示为 CN(=O)=O 或电荷分离 C[N+](=O)[O-] (我们倾向于使用前者用于数据库工作,因为它保持对称性)。两者都是“正确的”,因为它们代表了物质的不同的,有用的模型。 一般来说,当对称性不成问题时,大多数化学家更喜欢电荷分离结构,如果它们可以避免代表处于不寻常价态的原子。例如,重氮甲烷写成 C=[N+]=[N-] 而不是 C=[N]=[N]。
互变异构体
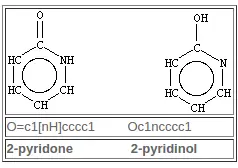
在 SMILES 中明确指定了互变异构结构。 没有“互变异构键”,“移动氢”,也没有“移动电荷”规范。 选择一种或所有互变异构结构留给使用者并且很大程度上取决于应用。 给定一种互变异构形式,如果需要,大多数化学信息系统将报告所有已知互变异构体的数据。SMILES 的作用是确切地指定请求哪种互变异构形式,以及哪些有数据。 一个简单的例子,有两种可能的互变异构形式,如下所示:
获取
自己手打后转换,或在网络上乞讨x
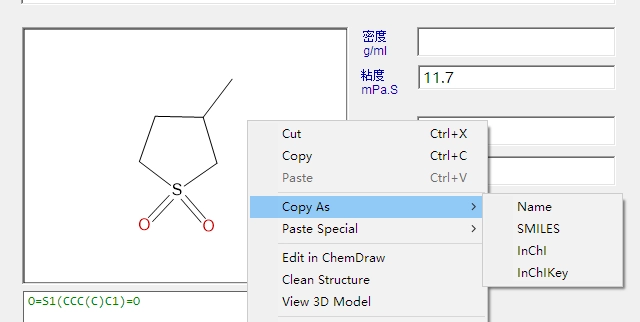
利用 ChemFinder 从数据库中储存的结构中获取
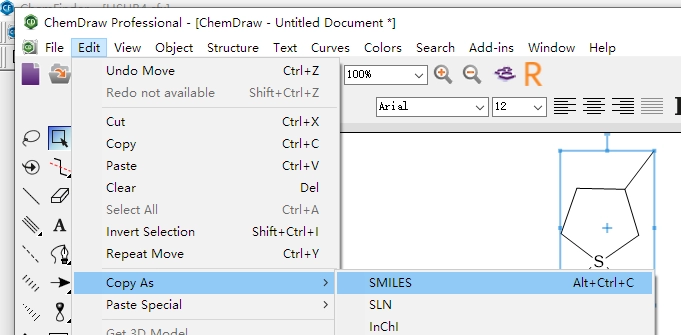
在 ChemDraw 中编辑好结构后导出
利用
在 ChemDraw 中,将复制的 SMILES 直接特殊粘贴